

Automatischer Bildzuschnitt
| Inhaltsverzeichnis |
Oft muss Bildmaterial erst zugeschnitten werden, damit es optimal für eine Webseite genutzt werden kann: Wenn beispielsweise Proportionen des Ausgangsbildes nicht zu den Proportionen und Größen passen die für die Internetpräsenz benötigt werden. Oder wenn bei Bildern mit mehreren Motiven bzw. Objekten ein bestimmter Ausschnitt in den Mittelpunkt gerückt werden soll.
Darüber hinaus arbeitet FirstSpirit mit so genannten „Auflösungen“ (siehe dazu Auflösungen (→Dokumentation für Administratoren)): Portenziell muss für jede Auflösung eines Bildes ein passender Ausschnitt durch den Redakteur gewählt werden.
Das Modul „FirstSpirit Image Assistant“ bietet dem Redakteur bei der Bildbearbeitung Unterstützung in unterschiedlichem Ausmaß: vollautomatischer Zuschnitt oder Motiverkennung. Alternativ kann das Modul auch dazu verwendet werden, um gestauchte Bilder zu vemeiden, wenn beispielsweise Auflösungen mit fest definiertem Seitenverhältnis im Projekt vorliegen. Außerdem, bietet das Modul die Möglichkeit der KI-gestützten Alt-Text-Generierung.
Das Modul "FirstSpirit Image Assistant"
Das Modul integriert eine KI-unterstützte Bilderkennung („Künstliche Intelligenz“) in die Redaktionsprozesse, so dass Gesichter, Objekte und Texte auf Bildern automatisch erkannt werden. Die Informationen werden als „Tags“ zu den Bildern gespeichert (samt Oberbegriffen und Synonymen), und zwar als FirstSpirit-Metadaten, z. B.
Person, Laptop, Door, Chair, Pants, Clothing usw.
Sie stehen in der FirstSpirit-Suche bereit, ermöglichen ein schnelles Wiederfinden und unterstützen somit eine effiziente Organisation der Bilder.
Das Modul weiß aber nicht nur, was sich auf einem Bild befindet, sondern auch wo: die Tags sind mit Koordinaten auf dem Bild verknüpft.
Die Analyse der Bilder erfolgt über den Bilderkennungsdienst „Amazon Rekognition“. Dieser liefert Tags und Koordinaten zu den erkannten Motiven eines Bildes zurück. Diese werden dann bei korrekter Metadaten-Konfiguration zu den analysierten Bilden in FirstSpirit hinterlegt.
Des Weiteren ermöglicht das Modul die KI-gestützte automatische Generierung von Alt-Texten.
Vollautomatischer Zuschnitt ("AutoCropping")
Auf Basis dieser Informationen können Bilder (inklusive aller Auflösungen) direkt beim Upload komplett automatisch zugeschnitten werden. Die Künstliche Intelligenz erkennt die Motive auf jedem Bild und leitet mithilfe einer an die jeweiligen Anforderungen anpassbaren Strategie das Hauptmotiv ab. Auf dieser Basis erstellt FirstSpirit automatisch passende Zuschnitte, die harmonisch und professionell wirken. FirstSpirit erzeugt auf diese Weise von jeder Art von Ausgangs-Bildmaterial die richtigen Formate für jeden Ihrer Online-Kanäle – ohne dass manueller Eingriff erforderlich wäre.
Für automatische Zuschnitte werden Motive standardmäßig in folgender Reihenfolge erkannt:
- Gesicht
Wird ein Gesicht erkannt, wird dieses als Fokusbereich verwendet. - mehrere Gesichter
Werden mehrere Gesichter erkannt, ist der Fokusbereich ein Rahmen um alle Gesichter.
(Around 4 faces) - Objekt
Wird ein Objekt erkannt, wird dieses als Fokusbereich verwendet. - mehrere Objekte
Werden mehrere Objekte erkannt, ist der Fokusbereich ein Rahmen um alle Objekte.
Diese Reihenfolge bzw. der Analyseschwerpunkt kann beeinflusst werden, und zwar durch das Erstellen von Medien-Ordnern mit geeigneten Metadaten: Wird ein Bild in den betreffenden Ordner hochgeladen, werden vorrangig solche Motive erkannt, die in den Metadaten definiert sind.
Siehe dazu auch Erkennung und automatisches Setzen des Fokusbereichs beeinflussen.
Hinweis: In manchen Fällen liefert die Analyse durch die Amazon Rekognition-API zwar Tags zurück, aber diese können nicht verortet werden. Dies ist kein Fehler von FirstSpirit. Es werden nur Fokusbereiche zu Motiven bereitgestellt, die durch die Amazon Rekognition-API verortet werden können.
Motiverkennung ("Fokusbereiche")

Alternativ können Sie statt des automatischen Zuschnitts auch die Analysefunktion gesondert dafür einsetzen, Motive auf Bildern automatisch zu erkennen (auch „Fokusbereiche“ genannt). Diese werden per Rahmen markiert, und Sie können den gewünschten Ausschnitt komfortabel mit nur einem Klick auswählen. Die Zuschnitte für alle benötigten Formate werden automatisch erzeugt. Für maximale Kontrolle und Genauigkeit können Sie die Zuschnitte noch einer manuellen Feinabstimmung unterziehen.
Einschränkungen und Empfehlungen
- Rechtliches: Bei Verwendung des Moduls „FirstSpirit Image Assistant“ und einer entsprechenden Projektkonfiguration werden Bilder beim Upload nach FirstSpirit oder per manuellem Auslösen der Funktionalität durch Amazon Rekognition analysiert. Die Verwendung des Dienstes ist DSGVO-konform.
- Finanzielles: Die Verwendung von Amazon Rekognition ist prinzipiell kostenpflichtig. Ein monatliches Kontingent an analysierten Bildern, das in den meisten Kundenszenarien ausreichend ist, ist in Ihrem Cloud-Offering bereits enthalten. Eventuell darüber hinaus anfallende Kosten werden separat in Rechnung gestellt.
- Bildformate: Derzeit werden die Bildformate JPEG, PNG und WebP unterstützt. Zu Bildern anderer Formate werden keine Metadaten hinterlegt. Somit ist kein automatischer Zuschnitt möglich, und es sind keine automatisch ermittelten Fokusbereiche verfügbar.
- Bildgröße und -auflösung: Für ein optimales Analyseergebnis gibt es seitens Amazon Rekognition Empfehlungen für die Auflösung und Mindestgröße von Bildern und den zu erkennenden Gesichtern und Objekten. Unscharfe Bilder können die Qualität des Analyseergebnisses beeinträchtigen. Siehe dazu auch Dokumentation zu "Amazon Rekognition".
- Amazon-seitige Daten: Die Logik, die bei der Analyse von Bildern verwendet wird, basiert auf den APIs von Amazon Rekognition. Ob und was auf Bildern erkannt wird, liegt nicht im Einflussbereich von Crownpeak.
Crownpeak kann versuchen, Probleme, die bei der Bildanalyse durch die Verwendung der Amazon-API entstehen, programmiertechnisch zu beheben – ein Anspruch darauf besteht nicht. - Sprache: Die von Amazon Rekognition zurückgelieferten Daten sind englischsprachig.
Modul: Installation und Konfiguration
 |
Dieser Schritt ist nur für Nicht-Cloud-Kunden notwendig. |
Nicht-Cloud-Kunden müssen zunächst das Modul installieren:
imagerecognition-module-[version].fsm
(Siehe dazu auch Module (→Dokumentation für Administratoren).)
Ist der Dienst „FS Image Assistant - AWS Connector“ gestartet (Standardeinstellung), werden Bilder beim Upload mit passendem Seitenverhältnis angelegt: Es kommt nicht mehr zu einem potenziellen Stauchen der Bilder.
- Sollen in analysierten Bildern Fokusbereiche angezeigt werden, müssen dazu entsprechende Metadaten-Felder in der Metadaten-Vorlage des jeweiligen Projekts definiert werden (siehe dazu Vorlagenentwicklung).
- Sollen Bilder automatisch zugeschnitten werden, muss dazu zusätzlich die Option „Autom. Zuschnitt standardmäßig aktiv“ aktiviert werden: entweder global für alle Projekte des Servers (siehe dazu folgenden Schritt) oder für einzelne Projekte (siehe dazu Projekt-Komponente).
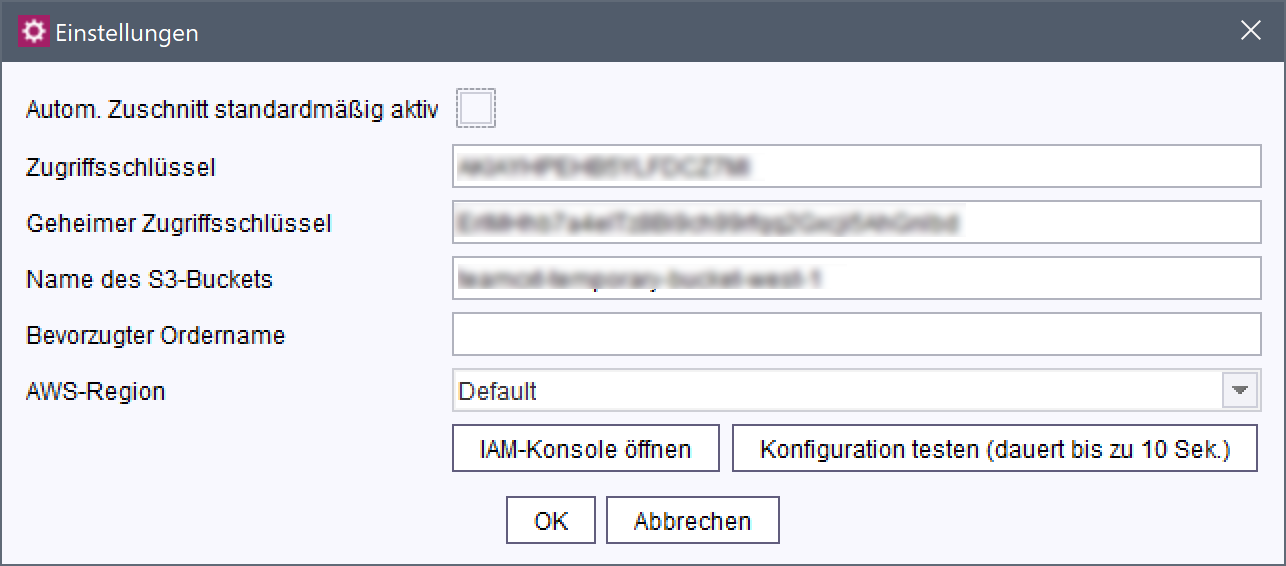
Konfiguration des „FS Image Assistant - AWS Connector“
Autom. Zuschnitt standardmäßig aktiv: Um den automatischen Zuschnitt von Bildern serverweit zu aktivieren, muss diese Checkbox aktiviert werden. Standardmäßig werden Bilder nicht automatisch zugeschnitten.
Diese globale Einstellung kann durch eine entsprechende Einstellung in einem Projekt jedoch überschrieben werden (Projekt-Komponente „FS Image Assistant - Configuration“, Checkbox „Automatischer Zuschnitt aktiv“).
Siehe dazu auch De-/Aktivieren der Funktionalität.
Zugriffsschlüssel: Zugriffsschlüssel des jeweiligen IAM-Benutzers (IAM = AWS Identity and Access Management, siehe AWS Dokumentation (IAM)).
Geheimer Zugriffsschlüssel: Geheimer Zugriffsschlüssel des jeweiligen IAM-Benutzers.
Name des S3-Buckets: (optional) Zum Analysieren von Bildern, die größer als 5 MB sind, wird ein sogenannter „Bucket“ benötigt. Dort werden die Bilder nur temporär zwischengespeichert.
Zu weiteren Informationen siehe auch AWS-Dokumentation (Buckets).
Bleibt dieses Feld leer, wird S3 nicht verwendet, und es können nur Bilder mit einer Größe < 5 MB analysiert werden.
Bevorzugter Ordnername: (optional) Es kann ein AWS-Ordner angegeben werden, in den die nach FirstSpirit hochgeladenen Bilder gespeichert werden.
Erlaubte Zeichen: Ziffern, Buchstaben, . (Punkt), - (Bindestrich) und _ (Unterstrich)
Ordnernamen müssen mit Buchstaben oder Ziffern starten und enden sowie mindestens zwei Zeichen lang sein.
Standardmäßig (wenn in diesem Feld nichts angegeben wird) werden die Bilder auf oberster Ebene des konfigurierten S3 Buckets gespeichert.
AWS-Region: Der Default nutzt die automatisch erkannte Region, falls es sich um einen AWS-Host handelt, andernfalls Irland.
IAM-Konsole öffnen: Öffnet die IAM-Konsole.
Konfiguration testen: Die Konfiguration wird getestet.
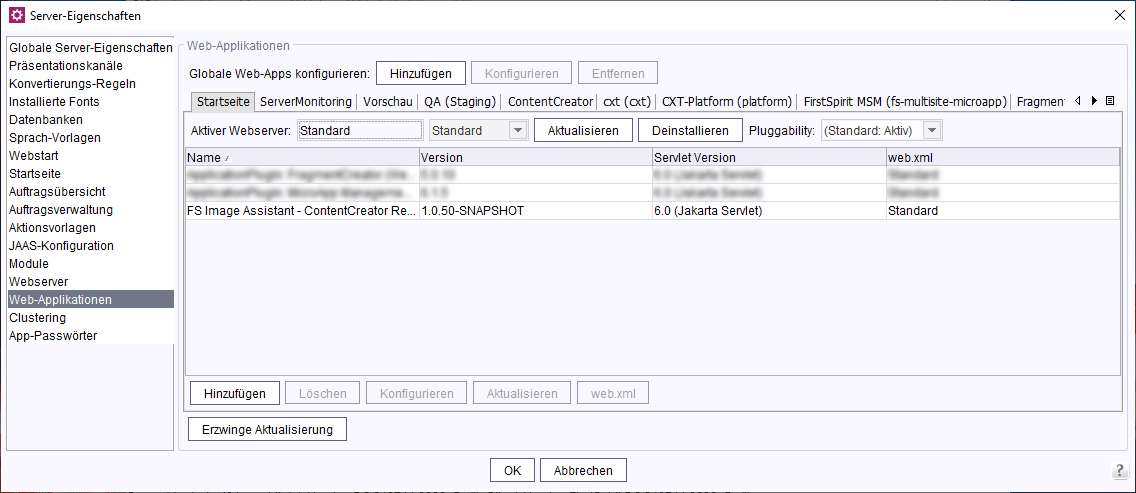
Hinzufügen der Web-Komponente
Anschließend muss die Web-Komponente „FS Image Assistant - ContentCreator Resources“ zur globalen ContentCreator-WebApp hinzugefügt werden.
Die WebApp muss dann aktualisiert / deployt werden (Aktiver Webserver: Button „Aktualisieren“).
Siehe dazu auch Web-Applikationen (→Dokumentation für Administratoren).
De-/Aktivieren der Funktionalität
Die automatische Bildzuschnitt-Funktionalität des Moduls „FirstSpirit Image Assistant“ umfasst mehrere Teilfunktionen. Standardmäßig wird weder ein automatischer Zuschnitt von Bildern vorgenommen, noch werden Fokusbereiche vorgeschlagen. Bilder können manuell zugeschnitten werden, je nach Bedarf mit System-Unterstützung oder ohne (siehe dazu Dokumentation zum ContentCreator).
Um die automatische Bildzuschnitt-Funktionalitäten des Moduls nutzen zu können, sind Konfigurationseinstellungen erforderlich, die im Folgenden beschrieben werden (per Projekt-Komponente und/oder Metadaten).
Bei Bedarf können Sie alle Teilfunktionen des Moduls „FirstSpirit Image Assistant“projektweise aktivieren bzw. wieder deaktivieren.
Voraussetzung generell ist, dass für die jeweilige Auflösung in den Projekteigenschaften die Option „SmartCropping“ aktiviert ist (siehe dazu Auflösungen (→Dokumentation für Administratoren)).
Beschreibung | Projekt-Komponente | Metadaten | |
|---|---|---|---|
Automatischer Zuschnitt | Bilder werden automatisch zugeschnitten. | aktiv | aktiv |
Manuelle Motivwahl | Es erfolgt kein automatischer Zuschnitt von Bildern. | deaktiv | aktiv |
Bildzuschnitt mittig | Es wird automatisch ein Zuschnitt vorgenommen, der von der Bildmitte ausgeht. Der Fokusbereich trägt die Bezeichnung „Image center“. Alle Auflösungen werden größtmöglich und mit passendem Seitenverhältnis zugeschnitten. | aktiv | deaktiv |
Deaktivierung der Modul-Funktionalität | Es wird weder ein automatischer Zuschnitt von Bildern vorgenommen, noch werden Fokusbereiche vorgeschlagen. | deaktiv | deaktiv |
Legende
Metadaten: Die von Amazon Rekognition zurückgelieferten Daten werden in Metadaten-Feldern von Bildern gespeichert. Dazu müssen diese Metadaten-Felder in der Metadaten-Vorlage mit spezifischen Bezeichnern definiert werden.
Siehe dazu Vorlagenentwicklung.
Bilder werden nur nach den Inhaltstypen analysiert, für die Metadaten-Felder definiert sind.
- „Metadaten aktiv“: Es ist mindestens eines der Metadaten-Felder definiert.
- „Metadaten deaktiv“: Es sind keine Metadaten-Felder definiert, und es wird keine Analyse vorgenommen.
Projekt-Komponente: Ob der automatische Zuschnitt zum Einsatz kommt, kann durch eine Einstellung im FirstSpirit ServerManager projektweise im Bereich „Projekt-Komponenten“ gesteuert werden.
Durch De-/Aktivieren der Checkbox „Automatischer Zuschnitt aktiv“ in der Projekt-Komponente „FS Image Assistant - Configuration“ kann die Funktionalität für das jeweilige Projekt aktiviert bzw. wieder deaktiviert werden.
(Siehe dazu auch Projekt-Komponenten (→Dokumentation für Administratoren).)
Projektlokale ContentCreator-Instanzen
Prinzipiell wird pro FirstSpirit-Server eine ContentCreator-Instanz verwendet. Man spricht dann auch vom ContentCreator als „globale“ Web-Applikation.
In manchen Fällen kann es gewünscht sein, eigene ContentCreator-Instanzen für einzelne Projekte eines FirstSpirit-Servers zu erstellen und zu betreiben. Auf diesen Instanzen kann dann spezifische Funktionalität bereitgestellt werden, beispielsweise per Modul. In diesem Fall spricht man auch vom ContentCreator als „projektlokale“ Instanz (siehe dazu auch Individualisierung der Webanwendungen (→Dokumentation für Administratoren)).
Aus Ressourcen- sowie Wartungsgründen wird empfohlen, den ContentCreator als globale Web-Applikation zu verwenden.
Soll die automatische Bildzuschnitt-Funktionalität trotzdem (beispielsweise für Testzwecke) nur für einen projektlokalen ContentCreator konfiguriert werden, muss der gewünschten Instanz die Web-Komponente „FS Image Assistant - ContentCreator Resources“ hinzugefügt werden, und zwar im FirstSpirit ServerManager, Projekteigenschaften / Web-Komponenten / Bereich „ContentCreator“). Siehe dazu auch Web-Komponenten (→Dokumentation für Administratoren).
Nach dem Hinzufügen der Web-Komponente muss diese Änderung deployed werden (Schaltfläche „Aktualisieren“ bzw. „Installieren“). Während des Deployments steht der entsprechende ContentCreator Redakteuren kurzzeitig nicht zur Verfügung.
Vorlagenentwicklung
Metadaten-Vorlage
Die Daten, die Amazon Rekognition zurückliefert, werden als Metadaten zum jeweiligen Bild gespeichert.
Dazu muss eine Metadaten-Vorlage im Projekt vorhanden sein (siehe dazu auch Optionen (→Dokumentation für Administratoren)).
Damit Bilder auf die folgenden Informationen hin analysiert werden, müssen Komponenten vom Typ CMS_INPUT_TEXTAREA mit den folgenden Bezeichnern erstellt werden:
- fsai_facesPayload: In diesem Feld werden von Amazon zurückgelieferte Informationen zu erkannten Gesichtern zum jeweiligen Bild gespeichert.
- fsai_objectsPayload: In diesem Feld werden von Amazon zurückgelieferte Informationen zu erkannten Objekten zum jeweiligen Bild gespeichert.
- fsai_textPayload: In diesem Feld werden von Amazon zurückgelieferte Informationen zu erkannten Texten zum jeweiligen Bild gespeichert.
- fsai_unsafeContentPayload: In diesem Feld werden von Amazon zurückgelieferte Informationen zu potenziell unangemessenen Inhalten zum jeweiligen Bild gespeichert.
- fsai_celebritiesPayload: In diesem Feld werden von Amazon zurückgelieferte Informationen zu erkannten Prominenten zum jeweiligen Bild gespeichert.
- fsai_tags: In diesem Feld werden die von Amazon zurückgelieferten „Tags“ (samt Oberbegriffen und Synonymen) zum jeweiligen Bild gespeichert. Diese Daten können für eine Verschlagwortung genutzt werden.
Empfehlung: Jede Analyse eines Bildes auf eine der oben aufgelisteten Kategorien stellt einen gebührenpflichtigen Aufruf der jeweiligen Amazon API dar. Daher sollten Sie nur die Metadaten erheben, die für Ihre Bilder und Ihren Anwendungsfall relevant sind. Die Felder fsai_textPayload, fsai_unsafeContentPayload und fsai_celebritiesPayload sind in der Regel nur für spezielle Anwendungsfälle erforderlich.
Erkennung und automatisches Setzen des Fokusbereichs beeinflussen
Nicht immer ist das Gesicht auf einem Bild das Hauptmotiv. Um zu beeinflussen, welche Bildbestandteile vorrangig als Fokusbereich genutzt werden sollen, können Medien-Ordner mit geeigneten Metadaten versehen werden. Je nachdem, in welchen Ordner ein Bild hochgeladen wird, wird dann das durch die Metadaten bestimmte Objekt vorrangig als Fokusbereich verwendet.
Dazu muss in den Metadaten eine Eingabekomponente vom Typ CMS_INPUT_TEXTAREA mit dem Bezeichner
fsai_focusPreference
verwendet werden.
In das Metadaten-Formular des betreffenden Medien-Ordners müssen die gewünschten Begriffe eingegeben werden. Um welchen Begriff es sich jeweils handelt, kann anhand der Metadaten bereits analysierter Bildern geprüft werden. Diese werden in der Komponente fsai_tags der Metadaten gespeichert.
Beispiel:
Car
Für ein besseres Ergebnis können auch mehrere Begriffe verwendet werden, um so die Bilderkennung nicht zu stark einzuschränken.
Mehrere Begriffe müssen durch Komma separiert werden, z. B.
Tablet Computer, Mobile Phone
Dabei werden nur Objekte berücksichtigt, für die ein Fokusbereich erkannt wird. Die Begriffe werden in der angegebenen Reihenfolge analysiert (das bedeutet: der erste Begriff ist am höchsten priorisiert).
Metadaten, die auf einem Ordner definiert sind, gelten standardmäßig auch für potenzielle Unterordner. Auf diese Weise können Metadaten für hierarchisch abhängige Teilbäume komfortabel wiederverwendet werden. Die Vererbung kann aber auch deaktiviert werden. Siehe dazu Dokumentation zum ContentCreator oder Metadaten (→Handbuch FirstSpirit SiteArchitect).
Werden in fsai_focusPreference keine Werte eingetragen, kommt das ursprüngliche Verhalten bei der automatischen Fokusbereich-Wahl zum Tragen.
Beispiel-Formular:
<CMS_INPUT_TEXTAREA name="fsai_focusPreference">
<LANGINFOS>
<LANGINFO lang="*" label="FS AI - Focus Preferences"/>
</LANGINFOS>
</CMS_INPUT_TEXTAREA>
<CMS_INPUT_TEXTAREA name="fsai_facesPayload">
<LANGINFOS>
<LANGINFO lang="*" label="FS AI - Faces Payload"/>
</LANGINFOS>
</CMS_INPUT_TEXTAREA>
<CMS_INPUT_TEXTAREA name="fsai_objectsPayload">
<LANGINFOS>
<LANGINFO lang="*" label="FS AI - Objects Payload"/>
</LANGINFOS>
</CMS_INPUT_TEXTAREA>
<CMS_INPUT_TEXTAREA name="fsai_textPayload">
<LANGINFOS>
<LANGINFO lang="*" label="FS AI - Text Payload"/>
</LANGINFOS>
</CMS_INPUT_TEXTAREA>
<CMS_INPUT_TEXTAREA name="fsai_unsafeContentPayload">
<LANGINFOS>
<LANGINFO lang="*" label="FS AI - Unsafe Content Payload"/>
</LANGINFOS>
</CMS_INPUT_TEXTAREA>
<CMS_INPUT_TEXTAREA name="fsai_celebritiesPayload">
<LANGINFOS>
<LANGINFO lang="*" label="FS AI - Celebrities Payload"/>
</LANGINFOS>
</CMS_INPUT_TEXTAREA>
<CMS_INPUT_TEXTAREA name="fsai_tags">
<LANGINFOS>
<LANGINFO lang="*" label="FS AI - Tags"/>
</LANGINFOS>
</CMS_INPUT_TEXTAREA>
Die Bezeichner der Komponenten (Attribut name) müssen exakt so verwendet werden, um die Funktionalität zu gewährleisten.
Metadaten im ContentCreator
Um die Informationen, die Amazon zu einem Bild zurückliefert, einzusehen, kann grundsätzlich der FirstSpirit SiteArchitect verwendet werden (siehe dazu auch Metadaten (→Handbuch FirstSpirit SiteArchitect)).
Um das Metadaten-Formular im FirstSpirit ContentCreator einsehen zu können, muss dies entsprechend konfiguriert werden, und zwar im FirstSpirit ServerManager, Projekteigenschaften / ContentCreator / Bereich „Metadaten“ (siehe dazu auch ContentCreator (→Dokumentation für Administratoren)).
Auflösungen ausschließen
Standardmäßig wird die automatische Bildzuschnitt-Funktionalität auf alle Auflösungen eines Projekts angewendet.
Sollen für eine oder mehrere Auflösungen keine automatischen Fokusbereiche bestimmt und somit kein automatischer Zuschnitt vorgenommen werden, kann dies pro Auflösung in den Projekteinstellungen konfiguriert werden.
Und zwar im FirstSpirit ServerManager, Projekteigenschaften / Auflösungen / Option „SmartCropping“ (siehe dazu auch Auflösungen (→Dokumentation für Administratoren)).
Standardmäßig ist die Option „SmartCropping“ für alle Auflösungen eines Projekts aktiviert. Damit wird bei Verwendung des Moduls „Image Assistant“ zu jeder Auflösung automatisch ein Fokusbereich festgelegt und / oder der Zuschnitt vorgenommen.
Wird die Option deaktiviert, wird für die betreffende Auflösung kein Fokusbereich festgelegt und kein Zuschnitt vorgenommen.
Diese Auflösungen finden sich im Zuschnittsdialog des jeweiligen Bilds in der Gruppe „Manuelle Zuschnitte“; für diese können Redakteure den gewünschten Zuschnitt manuell wählen (siehe dazu auch Dokumentation zum ContentCreator).
Von Amazon zurückgelieferte Daten
Die von Amazon zurückgelieferten Daten werden als Metadaten in den betreffenden Metadaten-Feldern zum jeweiligen Bild gespeichert. Und zwar in JSON-Format.
Eine detaillierte Dokumentation der von Amazon Rekognition zurückgelieferten Daten findet sich in der entsprechenden API zu Amazon Rekognition:
- DetectFaces
(Erkennung von Gesichtern) - DetectLabels
(Erkennung von Objekten)
Weiterführende Informationen
- Auflösungen: Auflösungen (→Dokumentation für Administratoren)
- Metadaten-Vorlage: Optionen (→Dokumentation für Administratoren)
- Bedienung durch den Redakteur
- Amazon Rekognition Image