

Searching and indexing
The search options in the FirstSpirit clients can be used by editors and developers to help them navigate within projects more easily and to enable them to quickly locate and edit existing content.
FirstSpirit's search functionality uses “Apache Lucene”. Every time FirstSpirit elements (such as pages, sections, and media) are created, edited, or deleted, the content and data relating to said elements is either automatically written to the search index or removed from it. This ensures that elements can be found quickly when they are searched for.
Recalculation of the search index for a project can also be initiated in line with a schedule task or via API, such as in the event that the indexing configuration has been amended.
Depending on the structure and scope of the project in question, indexing can require a relatively large amount of time and resources. FirstSpirit has several configuration parameters that can be used to determine which content actually needs to be indexed and the priority with which this should happen.
Project-specific search functions and enhancements can be implemented via the FirstSpirit Developer API: interface QueryAgent (package de.espirit.firstspirit.agency).
Recalculating the search index
The options for recalculating the FirstSpirit search index are as follows:
- Server-wide
“Renew search index of all projects” function (Server (→Documentation for Administrators)) - Project-wide
“Rebuild search index” action (Rebuild search index (→Documentation for Administrators)) - Via FirstSpirit Access API
Interface ProjectStorage (package de.espirit.firstspirit.access.admin)
Influencing the indexing of content at form level
searchRelevancy
This parameter can be set at form level. It is used to define the priority with which content is displayed within the search results. For example, it is possible to amend the settings such that search word occurrences in headline fields will be considered to be more relevant in the search results than occurrences of search words in body text fields. There is also the option to exclude input components from search indexing entirely, which can increase the overall performance of indexing.
 |
Content of input components for which the parameter searchRelevancy="none" is set will not be indexed, regardless of the configuration of indexing.relationshipPathLengthToFollow and/or indexTreatment (see below). |
For further information, please also refer to the chapter Input components.
Influencing the indexing of content at form level, datasets
indexTreatment
 This parameter relates only to input components that reference datasets:
This parameter relates only to input components that reference datasets:
- FS_DATASET
- FS_INDEX (for the selection of datasets via “DatasetDataAccessPlugin”)
In projects with several database tables, datasets in one table can contain links to datasets in other tables. In projects with complex data structures, these links may even extend across several tables. Linking several datasets across several tables can be described as a “path”. A direct link between datasets in two tables can be described as path length “1”. A path length of “2”, on the other hand, means that, alongside the “origin” dataset, datasets that are referenced by the output dataset are also indexed as well as datasets that are referenced by the referenced datasets:

By default, when indexing content that is being taken into account for a search, the content of directly referenced datasets (path length “1”) is also indexed in the case of the above-mentioned input components for datasets. This means that a search for a term from the dataset of a table 2 will also return referenced datasets from table 1, and vice versa.
The parameter indexTreatment can be used to influence the indexing of datasets in tables that are further removed. If indexTreatment="follow" is set, datasets that are referenced via the relevant input components will also be taken into account when indexing the origin dataset. If the parameter is not set (corresponds to indexTreatment="default"), referenced datasets will be indexed too in line with the configuration of indexing.relationshipPathLengthToFollow (see below).
This means that the indexing can only ever be extended by setting indexTreatment, but not restricted.
|
Datasets that are in the same table will not be included in the indexing. |
For examples of configurations with indexTreatment, refer also to the “Configuration examples for dataset indexing” section below.
Influencing the indexing of content at server level, datasets
indexing.relationshipPathLengthToFollow
This parameter (fs-server.conf) can be used to define which path length should be taken into account when indexing. By default, datasets and referenced datasets are indexed. This reflects a path length of 1. A path length of 2, on the other hand, means that, alongside the current dataset, datasets that are referenced by the current dataset are also indexed as well as datasets that are referenced by the referenced datasets.
The indexing behavior illustrated here also applies to referenced datasets in pages and sections. The page or section in which the dataset-referencing input component is located is considered to be path length 0. With indexing.relationshipPathLengthToFollow=0, only the contents of the page or the section would be indexed. In order to also index contents of the referenced dataset, indexing.relationshipPathLengthToFollow must be set to a value of “1”.
For further information, please refer to the “FirstSpirit Documentation for Administrators” (Server (→Documentation for Administrators)).
For examples of configurations with indexing.relationshipPathLengthToFollow, refer also to the “Configuration examples for dataset indexing” section below.
indexing.extendedDatasetKeys
 This parameter (fs-server.conf) can be used to adjust the format of the search index when using external databases.
This parameter (fs-server.conf) can be used to adjust the format of the search index when using external databases.
If indexing.extendedDatasetKeys=true is set, the format of the search index is changed so that datasets from different tables with the same primary key can be found via the search.
The default value is indexing.extendedDatasetKeys=false. With this setting, only one of these datasets is found when using external databases.
|
After changing the parameter, the search index must be recalculated for all projects that use external databases (see Recalculating the search index). Otherwise, the old versions can still be found when changes are made to datasets. |
Influencing the indexing of content at project level, datasets
SearchIndexAgent
 Using the interface SearchIndexAgent (Package de.espirit.firstspirit.agency, FirstSpirit Developer-API), the parameter indexing.relationshipPathLengthToFollow (see above) may be overwritten for an individual project.
Using the interface SearchIndexAgent (Package de.espirit.firstspirit.agency, FirstSpirit Developer-API), the parameter indexing.relationshipPathLengthToFollow (see above) may be overwritten for an individual project.
This means that the indexing depth can be adjusted for single projects independently from the server-wide configuration. If there is no project-specific configuration set, the server-side parameter will be evaluated.
The iteration depth may now be adjusted, e.g. via script:
Example:
import de.espirit.firstspirit.agency.SearchIndexAgent;
sia = context.requestSpecialist(SearchIndexAgent.TYPE);
sia.setPathLengthToFollow(2);
Further information on Accessing FirstSpirit Functionality via Agents.
Configuration examples for dataset indexing
Below are some examples of the use of indexing.relationshipPathLengthToFollow and indexTreatment in a database schema with three tables that are linked linearly:
In a database schema given by way of example,
- “Products”
- “Contacts”
- “Locations”
are saved in three tables. A contact can be saved for each product, and one or more locations can in turn be selected and saved for each contact.
An employee with the surname “Smith” (from the “Contacts” table) is saved as the contact for the product “Accum 150” (“Products” table). In the “Contacts” table, “London” (from the “Locations” table) is saved as the location for “Smith”:
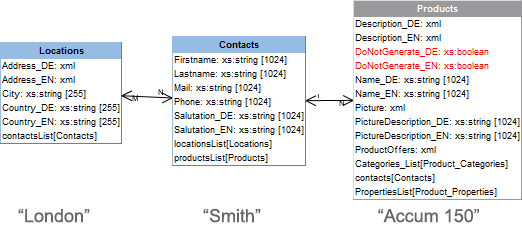
Indexing no referenced datasets
If each dataset is just to be indexed separately and no references to other datasets are to be taken into account, the parameter indexing.relationshipPathLengthToFollow=0 can be set.
Searching for “Smith”, “London”, or “Accum”, for example, will then only return the relevant dataset as a search result. However, searching for “London” will not return the “Smith” dataset from the “Contacts” table nor the “Accum 150” dataset from the “Products” table.
This configuration is a suitable option, for example, when there are lots of references across tables, which do not, however, play any role in a search and the performance is instead to be boosted when indexing and/or searching.
Including all directly referenced datasets in indexing
By default, when any dataset is being indexed, the next, directly referenced dataset will also be taken into account (path length 1). This corresponds to the configuration indexing.relationshipPathLengthToFollow=1 (which is the default value if the parameter is not explicitly set). This means that a search for “London” will deliver the “Smith” dataset from the “Contacts” table as well as the “London” dataset. As a result, this configuration makes it possible to also identify which employees (contacts) belong to a location from a search.
This configuration is ideal for less complex database structures, within which tables are linked with a path length of 1 and/or if hits from further removed tables are not to play any role in a search.
This indexing behavior applies to all database schemas and tables server-wide. To add referenced datasets from further removed tables to the search hits for special tables, the parameter indexTreatment="follow" can be used. For further information on this point, please refer to the “Indexing only special referenced datasets” section (below).
Including further removed datasets in indexing
If indexing.relationshipPathLengthToFollow=2 is set, referenced datasets from tables that are linked with a path length of 2 will be taken into account in indexing for any dataset alongside directly referenced datasets from the next table (path length 1).
This means that a search for “London” will deliver the “Smith” dataset from the “Contacts” table and the “Accum 150” dataset from the “Products” table as well as the “London” dataset from the “Locations” table.
As a result, this configuration makes it possible to identify which employees (contacts) belong to a location from a search as well as which products are linked to a location.
The parameter indexTreatment="follow" can also be used here when necessary to add referenced datasets from further removed tables to the search hits. For further information on this point, please refer to the “Indexing only special referenced datasets” section (below).
Indexing only special referenced datasets
If datasets from further tables which are not taken into account in indexing (due to the configuration via indexing.relationshipPathLengthToFollow) should become able to be found by search, this can be accomplished by setting the parameter indexTreatment="follow".
For example, if - in a standard configuration of indexing.relationshipPathLengthToFollow (path length 1) - the parameter indexTreatment="follow" is set for the input component in the “Products” table which is used to select the contact from the “Contacts” table (“contacts” column), after reindexing, a search for “London” will deliver the “London” dataset from the “Locations” table, the “Smith” dataset from the “Contacts” table, and the “Accum 150” dataset from the “Products” table. As a result, a search can be used to identify which products are linked to a location. For datasets that are referenced via an input component with the indexTreatment="follow" parameter, the result in this case will be similar to that achieved when indexing.relationshipPathLengthToFollow=2 is set.