

<MATCHES/>: Validierung mit regulären Ausdrücken
Das <MATCHES/>-Tag kann im Bereich Wertermittlung der Regeldefinition (oder für die Definition einer Vorbedingung) eingesetzt werden und dient zur Angabe eines regulären Ausdrucks in einer Regel.
Innerhalb des <MATCHES/>-Tags muss ein Vergleichswert angegeben werden, der sich auf eine bestimmte Eigenschaft des Formularelements (beispielsweise den Wert der Eingabekomponente) oder auch des Formulars („In welcher Sprache wurde das Formular geöffnet?“) bezieht. Dazu ist die Angabe eines <PROPERTY/>-Tags innerhalb des <MATCHES/>-Abschnitts notwendig.
Erfüllt der Vergleichswert die Bedingungen des regulären Ausdrucks, liefert der <MATCHES/>-Abschnitt TRUE zurück, andernfalls FALSE.
Attribut "regex"
Der reguläre Ausdruck wird über das Attribut „regex“ übergeben. Abhängig vom regulären Ausdruck kann das Vorkommen bestimmter Zeichen, Zeichenketten und Zeichenabfolgen innerhalb des Vergleichswerts untersucht und ausgewertet werden.
<MATCHES regex="ABC" />
Zu Informationen zur Syntax, die für das Attribut „regex“ verwendet werden kann, siehe http://docs.oracle.com/javase/7/docs/api/java/util/regex/Pattern.html.
 |
Aufgrund unterschiedlicher Regex-Engines kann das Verhalten des Attributs „regex“ im SiteArchitect und im ContentCreator leicht voneinander abweichen. |
|
Zeichen, die für das Attribut „regex“ verwendet werden sollen und in XML-Syntax eine besondere Bedeutung haben, müssen maskiert werden, z. B. muss - das Zeichen < durch < - das Zeichen & durch & - das Zeichen " durch " ersetzt werden. |
Beispiele
1) Sprachabhängige Validierung
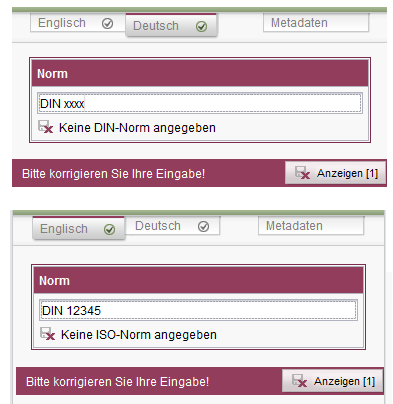
Im folgenden Beispiel wird abhängig von der aktuell bearbeiteten Redaktionssprache nur ein bestimmter Zweig der Regel durchlaufen. Die Eingabekomponente „st_standard“, für die die Regel definiert wird, erlaubt die sprachabhängige Angabe einer DIN- (für die Sprache „DE“) oder einer ISO-Norm (für die Sprache „EN“). Die Regel prüft über die Definition einer Vorbedingung, in welcher Sprache das Formular durch den Redakteur bearbeitet wird (Sprachabhängige Validierung).
Für beide Sprachen wird innerhalb der Regel ein unterschiedlicher regulärer Ausdruck definiert, der prüft, ob die Eingabe des Redakteurs für diese Sprache gültig sind.
<RULES>
<RULE>
<IF>
<EQUAL>
<PROPERTY source="#global" name="LANG"/>
<TEXT>DE</TEXT>
</EQUAL>
</IF>
<WITH>
<MATCHES regex="^DIN\ \d\d*$">
<PROPERTY source="st_standard" name="VALUE"/>
</MATCHES>
</WITH>
<DO>
<VALIDATION scope="SAVE">
<PROPERTY source="st_standard" name="VALID"/>
<MESSAGE lang="*" text="No DIN standard given"/>
<MESSAGE lang="DE" text="Keine DIN-Norm angegeben"/>
</VALIDATION>
</DO>
</RULE>
<RULE>
<IF>
<NOT>
<EQUAL>
<PROPERTY source="#global" name="LANG"/>
<TEXT>DE</TEXT>
</EQUAL>
</NOT>
</IF>
<WITH>
<MATCHES regex="^ISO\ \d\d*$">
<PROPERTY source="st_standard" name="VALUE"/>
</MATCHES>
</WITH>
<DO>
<VALIDATION scope="SAVE">
<PROPERTY source="st_standard" name="VALID"/>
<MESSAGE lang="*" text="No ISO standard given"/>
<MESSAGE lang="DE" text="Keine ISO-Norm angegeben"/>
</VALIDATION>
</DO>
</RULE>
</RULES>
2) Whitespaces unterbinden
Bei einigen Text-Eingabekomponenten (z. B. CMS_INPUT_TEXT) gelten (analog zum Parameter „allowEmpty“) auch Whitespaces (inkl. das Leerzeichen) als Inhalt, d. h. eine Text-Eingabekomponente gilt auch als „Nicht Leer“, wenn ausschließlich ein oder mehrere Leerzeichen eingegeben werden. Sollen reine Whitespace-Angaben verhindert werden, so ist diese Prüfung über Reguläre Ausdrücke realisierbar:
<RULES>
<RULE>
<WITH>
<NOT>
<MATCHES regex="^\s*$">
<PROPERTY name="VALUE" source="st_headline"/>
</MATCHES>
</NOT>
</WITH>
<DO>
<VALIDATION scope="SAVE">
<PROPERTY name="VALID" source="st_headline"/>
<MESSAGE lang="*" text="No content provided!"/>
<MESSAGE lang="DE" text="Es wurde kein Inhalt erfasst!"/>
</VALIDATION>
</DO>
</RULE>
</RULES>