

Suche und Indizierung
| Inhaltsverzeichnis |
Die Suchmöglichkeiten in den FirstSpirit-Clients unterstützen Redakteure und Entwickler bei der Orientierung im Projekt und beim schnellen Auffinden und Bearbeiten von bestehenden Inhalten.
Für die Suche in FirstSpirit wird „Apache Lucene“ verwendet. Mit jedem Anlegen, Bearbeiten oder Löschen von FirstSpirit-Elementen (z. B. Seiten, Absätze, Medien) werden die Inhalte und Daten der Elemente dabei automatisch in den Suchindex geschrieben bzw. aus diesem entfernt, um die Elemente bei einer Suche schnell wiederfinden zu können.
Die Neuberechnung des Suchindex eines Projekts kann auch per Auftrag oder API ausgelöst werden, beispielsweise wenn die Konfiguration der Indizierung geändert wurde.
Je nach Projektstruktur und -umfang kann eine Indizierung relativ viel Zeit und Ressourcen in Anspruch nehmen. FirstSpirit bietet einige Konfigurationsparameter, mit denen bestimmt werden kann, welche Inhalte tatsächlich indiziert werden sollen und ggf. mit welcher Gewichtung.
Projektspezfische Suchfunktionen bzw. -erweiterungen können über die FirstSpirit Developer-API umgesetzt werden: Interface QueryAgent (Package de.espirit.firstspirit.agency).
Neuberechnung des Suchindex
Folgende Möglichkeiten bestehen, um den FirstSpirit-Suchindex neu zu berechnen:
- Serverweit
Funktion „Suchindex aller Projekte erneuern“ (Server (→Dokumentation für Administratoren)) - Projektweit
Aktion „Suchindex neu aufbauen“ (Suchindex neu aufbauen (→Dokumentation für Administratoren)) - Per FirstSpirit Access-API
Interface ProjectStorage (Package: de.espirit.firstspirit.access.admin)
Beeinflussung der Indizierung von Inhalten auf Formularebene
searchRelevancy
Dieser Parameter kann auf Formularebene gesetzt werden. Er definiert, mit welcher Gewichtung Inhalte in Suchergebnissen angezeigt werden. So kann beispielsweise festgelegt werden, dass Suchtreffer aus Überschriftsfeldern prominenter in den Suchergebnissen angezeigt werden als Suchtreffer aus Fließtexten. Andererseits können auch Eingabekomponenten ganz von der Suchindizierung ausgenommen werden, was in einer erhöhten Performanz der Indizierung resultieren kann.
 |
Inhalte, die aus Eingabekomponenten stammen, für die der Parameter searchRelevancy="none" gesetzt ist, werden nicht indiziert, unabhängig von der Konfiguration von indexing.relationshipPathLengthToFollow und / oder indexTreatment (siehe unten). |
Zu weiteren Informationen siehe auch Kapitel Eingabekomponenten.
Beeinflussung der Indizierung von Inhalten auf Formularebene, Datensätze
indexTreatment
 Dieser Parameter betrifft nur Eingabekomponenten, die Datensätze referenzieren:
Dieser Parameter betrifft nur Eingabekomponenten, die Datensätze referenzieren:
- FS_DATASET
- FS_INDEX (zur Datensatzauswahl per „DatasetDataAccessPlugin“)
In Projekten mit mehreren Datenbank-Tabellen können Datensätze mit Datensätzen anderer Tabellen verknüpft sein, in Projekten mit komplexen Datenstrukturen auch über mehrere Tabellen hinweg. Die Verknüpfung von mehreren Datensätzen über mehrere Tabellen hinweg kann als „Pfad“ bezeichnet werden. Die direkte Verknüpfung von Datensätzen zweier Tabellen kann als Pfadlänge „1“ bezeichnet werden. Eine Pfadlänge von „2“ hingegen bedeutet, dass neben dem Ausgangs-Datensatz auch Datensätze indiziert werden, die vom Ausgangs-Datensatz referenziert werden sowie Datensätze, die von den referenzierten Datensätzen referenziert werden:

Bei einer Indizierung der Inhalte, die für eine Suche berücksichtigt werden, werden standardmäßig im Falle der oben genannten Eingabekomponenten zu Datensätzen auch die Inhalte von direkt referenzierten Datensätzen indiziert (Pfadlänge „1“). Das bedeutet, dass eine Suche nach einem Begriff aus dem Datensatz einer Tabelle 2 auch referenzierte Datensätze der Tabelle 1 liefert, und anders herum.
Mithilfe des Parameters indexTreatment kann die Indizierung von Datensätzen in weiter entfernten Tabellen beeinflusst werden. Wird indexTreatment="follow" gesetzt, werden Datensätze, die über die betreffende Eingabekomponenten referenziert werden, bei einer Indizierung des Ausgang-Datensatzes mit berücksichtigt. Wird der Parameter nicht gesetzt (entspricht indexTreatment="default"), werden referenzierte Datensätze gemäß der Konfiguration von indexing.relationshipPathLengthToFollow (siehe unten) mit indiziert.
Die Indizierung kann über das Setzen von indexTreatment also immer nur ausgeweitet werden, aber nicht eingeschränkt.
|
Datensätze, die sich in derselben Tabelle befinden, werden nicht mit indiziert. |
Zu Konfigurationsbeispielen mit indexTreatment siehe auch Abschnitt „Konfigurationsbeispiele für die Datensatz-Indizierung“ unten.
Beeinflussung der Indizierung von Inhalten auf Serverebene, Datensätze
indexing.relationshipPathLengthToFollow
Mithilfe dieses Parameters (fs-server.conf) kann definiert werden, welche Pfadlänge bei einer Indizierung berücksichtigt werden soll: Standardmäßig werden Datensätze sowie referenzierte Datensätze indiziert. Dies spiegelt eine Pfadlänge von 1 wider. Eine Pfadlänge von 2 hingegen bedeutet, dass neben dem aktuellen Datensatz auch Datensätze indiziert werden, die vom aktuellen Datensatz referenziert werden sowie Datensätze, die von den referenzierten Datensätzen referenziert werden.
Das hier beschriebene Indizierungsverhalten gilt auch für referenzierte Datensätze in Seiten und Absätzen. Die Seite oder der Absatz, in der/dem sich die Eingabekomponente zur Datensatzreferenzierung befindet, stellt dabei die Pfadlänge 0 dar. Mit indexing.relationshipPathLengthToFollow=0 würden also nur Inhalte der Seite bzw. des Absatzes indiziert. Um auch Inhalte des referenzierten Datensatzes mit zu indizieren, muss indexing.relationshipPathLengthToFollow auf den Wert „1“ gesetzt werden.
Zu weiteren Informationen siehe „FirstSpirit Dokumentation für Administratoren“ (Server (→Dokumentation für Administratoren)).
Zu Konfigurationsbeispielen mit indexing.relationshipPathLengthToFollow siehe auch Abschnitt „Konfigurationsbeispiele für die Datensatz-Indizierung“ unten.
indexing.extendedDatasetKeys
 Über diesen Parameter (fs-server.conf) kann das Format des Suchindexes bei der Verwendung externer Datenbanken angepasst werden.
Über diesen Parameter (fs-server.conf) kann das Format des Suchindexes bei der Verwendung externer Datenbanken angepasst werden.
Ist indexing.extendedDatasetKeys=true gesetzt, wird das Format des Suchindexes so geändert, das Datensätze aus verschiedenen Tabellen mit demselben Primary Key über die Suche gefunden werden können.
Standardwert ist indexing.extendedDatasetKeys=false. Mit dieser Einstellung wird bei der Verwendung externer Datenbanken nur einer dieser Datensätze gefunden.
|
Nach einer Änderung des Parameters muss der Suchindex für alle Projekte, die externe Datenbanken verwenden, neu berechnet werden (siehe Neuberechnung des Suchindex). Ansonsten können bei Änderungen an Datensätzen weiterhin die alten Versionen gefunden werden. |
Beeinflussung der Indizierung von Inhalten auf Projektebene, Datensätze
SearchIndexAgent
 Über das Interface SearchIndexAgent (Package de.espirit.firstspirit.agency, FirstSpirit Developer-API) kann der Parameter indexing.relationshipPathLengthToFollow (s.o.) projektspezifisch überschrieben werden.
Über das Interface SearchIndexAgent (Package de.espirit.firstspirit.agency, FirstSpirit Developer-API) kann der Parameter indexing.relationshipPathLengthToFollow (s.o.) projektspezifisch überschrieben werden.
Das heißt, die Indizierungstiefe kann für einzelne Projekte unabhängig von der serverseitigen Konfiguration angepasst werden. Ist keine projektspezifische Konfiguration gesetzt, wird weiterhin der serverseitige Parameter ausgewertet.
Die Iterationstiefe kann im Projekt beispielsweise folgendermaßen per Skript angepasst werden:
Beispiel:
import de.espirit.firstspirit.agency.SearchIndexAgent;
sia = context.requestSpecialist(SearchIndexAgent.TYPE);
sia.setPathLengthToFollow(2);
Weiterführende Informationen zur Verwendung von FirstSpirit-Funktionalität über Agents.
Konfigurationsbeispiele für die Datensatz-Indizierung
Im Folgenden einige Beispiele für die Verwendung von indexing.relationshipPathLengthToFollow und indexTreatment in einem Datenbank-Schema mit drei linear verknüpften Tabellen:
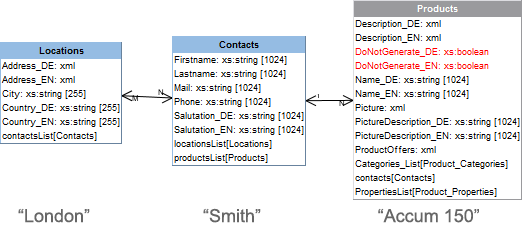
In einem beispielhaften Datenbankschema werden
- Produkte („Products“)
- Kontakte („Contacts“)
- Standorte („Locations“)
in drei Tabellen gespeichert. Zu jedem Produkt kann ein Kontakt hinterlegt, zu jedem Kontakt wiederum ein oder mehrere Standorte ausgewählt und gespeichert werden.
Als Kontakt für das Produkt „Accum 150“ (Tabelle „Products“) ist ein Mitarbeiter mit dem Nachnamen „Smith“ (aus der Tabelle „Contacts“) hinterlegt. In der Tabelle „Contacts“ ist für „Smith“ der Standort „London“ (aus der Tabelle „Locations“) hinterlegt:
Keine referenzierten Datensätze indizieren
Soll nur jeder Datensatz für sich indiziert und keine Referenzen zu anderen Datensätzen berücksichtigt werden, kann der Parameter indexing.relationshipPathLengthToFollow=0 gesetzt werden.
Eine Suche nach „Smith“, „London“ oder „Accum“ liefert dann beispielsweise nur den jeweiligen Datensatz als Suchergebnis, eine Suche nach „London“ allerdings weder den Datensatz „Smith“ aus der Tabelle „Contacts“ noch den Datensatz „Accum 150“ aus der Tabelle „Products“.
Diese Konfiguration bietet sich beispielsweise an, wenn viele Referenzen zwischen Tabellen bestehen, sie bei einer Suche aber keine Rolle spielen und stattdessen die Performance bei der Indizierung bzw. Suche gesteigert werden soll.
Alle direkt referenzierten Datensätze mit indizieren
Standardmäßig wird bei einer Indizierung zu jedem Datensatz auch der nächste, direkt referenzierte Datensatz berücksichtigt (Pfadlänge 1). Dies entspricht der Konfiguration indexing.relationshipPathLengthToFollow=1 bzw. der Parameter ist nicht gesetzt. Das bedeutet, eine Suche nach „London“ liefert neben dem Datensatz „London“ auch den Datensatz „Smith“ aus der Tabelle „Contacts“. Mit dieser Konfiguration kann also bei einer Suche ermittelt werden, welche Mitarbeiter (Kontakte) zu einem Standort gehören.
Diese Konfiguration ist empfehlenswert für weniger komplexe Datenbank-Strukturen, in denen Tabellen mit einer Pfadlänge von 1 verknüpft sind und / oder wenn bei einer Suche Treffer aus weiter entfernten Tabellen keine Rolle spielen.
Dieses Indizierungsverhalten gilt für alle Datenbankschemata und Tabellen serverweit. Um für spezielle Tabellen die Suchtreffer um referenzierte Datensätze aus weiter entfernten Tabellen zu erweitern, kann der Parameter indexTreatment="follow" verwendet werden. Siehe dazu Abschnitt „Nur spezielle referenzierte Datensätze indizieren“ (unten).
Weiter entfernte Datensätze mit indizieren
Wird indexing.relationshipPathLengthToFollow=2 gesetzt, wird bei einer Indizierung zu jedem Datensatz neben direkt referenzierten Datensätzen aus der nächsten Tabelle (Pfadlänge 1) auch referenzierte Datensätze aus Tabellen, die mit einer Pfadlänge von 2 verknüpft sind, berücksichtigt.
Eine Suche nach „London“ liefert damit neben dem Datensatz „London“ aus der Tabelle „Locations“ auch den Datensatz „Smith“ aus der Tabelle „Contacts“ und den Datensatz „Accum 150“ aus der Tabelle „Products“.
Mit dieser Konfiguration kann durch eine Suche ermittelt werden, welche Mitarbeiter (Kontakte) zu einem Standort gehören und auch, welche Produkte mit einem Standort verknüpft sind.
Auch hier kann der Parameter indexTreatment="follow" bei Bedarf verwendet werden, um die Suchtreffer um referenzierte Datensätze aus weiter entfernten Tabellen zu erweitern. Siehe dazu Abschnitt „Nur spezielle referenzierte Datensätze indizieren“ (unten).
Nur spezielle referenzierte Datensätze indizieren
Sollen Datensätze aus weiteren Tabellen auffindbar sein, die aufgrund der Konfiguration durch indexing.relationshipPathLengthToFollow bei einer Indizierung nicht berücksichtigt werden, kann dies durch Setzen des Parameters indexTreatment="follow" erreicht werden.
Wird bei einer Standardkonfiguration von indexing.relationshipPathLengthToFollow (Pfadlänge 1) der Parameter indexTreatment="follow" beispielsweise für die Eingabekomponente in der Tabelle „Products“ gesetzt, mit der der Kontakt aus der Tabelle „Contacts“ ausgewählt wird (Spalte „contacts“), liefert die Suche nach „London“ nach einer Neuindizierung zusätzlich zu den Datensätzen „London“ aus der Tabelle „Locations“ und „Smith“ aus der Tabelle „Contacts“ auch den Datensatz „Accum 150“ aus der Tabelle „Products“. So kann durch eine Suche ermittelt werden, welche Produkte mit eine Standort verknüpft sind. Für Datensätze, die über eine Eingabekomponenten mit dem Parameter indexTreatment="follow" referenziert sind, ist das Verhalten in diesem Fall somit vergleichbar mit dem Setzen von indexing.relationshipPathLengthToFollow=2.